
Qualcomm人工智能神经处理软件开发工具包
Qualcomm人工智能神经处理软件开发工具包(也被正式称为Snapdragon神经处理引擎(SNPE))是一种用于执行深度神经网络的软件加速、仅限推理的运行时间引擎。利用软件开发工具包,用户可以:
• 执行任意深度的神经网络
• 使用Hexagon张量加速器(HTA)在Kryo中央处理器、Adreno图形处理器或Hexagon数字信号处理器上执行网络
• 在x86乌班图Linux上调试网络执行情况
• 将Caffe、caff2、开放神经网络交换及张量流图模型转换为深度学习容器(DLC)文件
• 将数据链路控制文件量化为8位固定点,以便在Hexagon数字信号处理器上运行
• 使用Qualcomm神经处理软件开发工具包工具对网络进行性能调试和分析
• 通过C++或Java语言将网络集成到应用程序和其他代码中
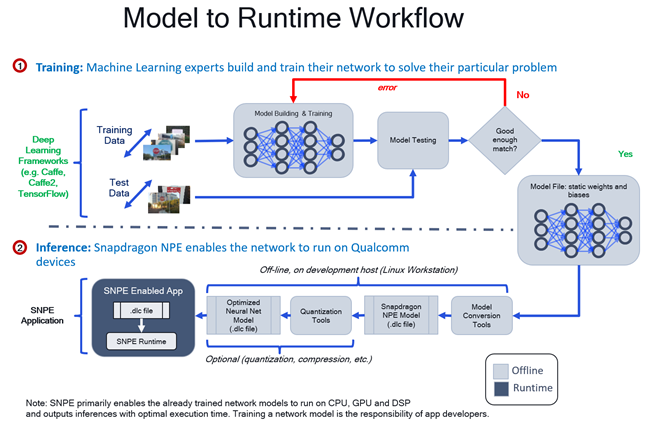
附图中显示了涉及Qualcomm神经处理软件开发工具包运行时间引擎的通用工作流程。在该工作流程中:
1. 开发人员/数据科学家可以开发模型,并对其进行培训以满足要求(培训阶段)。
2. 一旦某一模型经过训练并被冻结,这一具有静态权重和偏差的模型就会被转换为Qualcomm神经处理软件开发工具包的本机格式,即(数据链路控制)。
3.一旦生成了模型文件数据链路控制,就可以使用可选的离线优化工具对其进行优化。该等优化包括量化和压缩技术。
4. 开发人员可以使用Qualcomm神经处理软件开发工具包C++/Java应用程序接口或使用GStreamer插件(qtimlesnpe)编写机器学习用程序(Qualcomm神经处理软件开发工具包支持的应用程序),以快速执行转换后的模型。
5. 模型的性能和准确性可能需要进行调试。将调试工具作为Qualcomm神经处理软件开发工具包的组成部分予以提供。
运行时间工作流程模型
在QTI公司网站上可以获得Qualcomm神经处理软件开发工具包及其开发工作流程的完整参考指南。
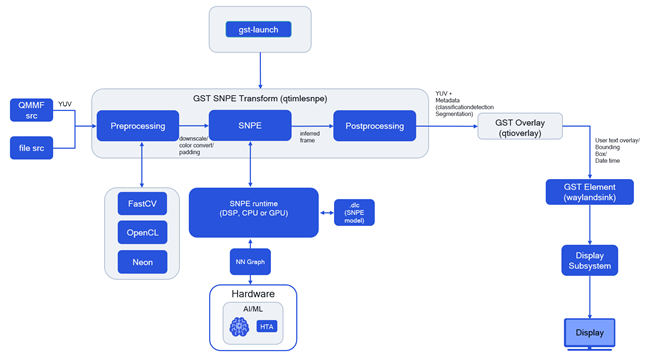
开发人员可以向可用GStreamer插件提供经过转换的深度学习容器模型,从而迅速整合其机器学习模型。GStreamer插件直接执行以下函数:
• 加载.dlc文件
• 视频帧的预处理和后处理
• 配置Qualcomm神经处理软件开发工具包,以便在数字信号处理器、中央处理器、图形处理器、或Hexagon张量加速器上运行
• 从Qualcomm神经处理软件开发工具包进行抽象化
在GStreamer启动时,来自摄像头源(亮度和色差信号)或文件源的推理帧将连同模型深度学习容器(按照Qualcomm神经处理软件开发工具包工作流程生成)一起交付于全球通信系统-Qualcomm神经处理引擎接收器(GStreamer-Qualcomm神经处理引擎插件)。发过来,GStreamer Qualcomm神经处理引擎槽将使用Qualcomm神经处理软件开发工具包运行时间将模型计算转移到所请求的运行时间(数字信号处理器、图形处理器或中央处理器)。推理结果被收集回全球通信系统-Qualcomm神经处理引擎接收器中进行后处理(例如,如果模型属于对象检测模型,则在帧中覆盖所检测对象上的边界框和类识别号)。以下示例展示了如何通过一个实时摄像头1080P数据流进行推理,并在亮度和色差信号数据流上应用一个内联的包围框覆盖。在Weston显示器上进行渲染。因此,形成XDG_RUNTIME_DIR集合。将相应的标签和模型分别推送到标签和配置变量中所引用的文件夹中。

Qualcomm 开发者专区是 Qualcomm 联合CSDN 共同打造的面向中国开发者的技术专区。致力于通过提供全球最新资讯和最多元的技术资源及支持,为开发者们打造全面一流的开发环境。本专区将以嵌入式、物联网、游戏开发、Qualcomm® 骁龙™处理器的软件优化等技术为核心,打造全面的开发者技术服务社区,为下一代高性能体验和设计带来更多的想法和灵感。
加入 Qualcomm 开发者专区

申请成为“Qualcomm荣誉技术大使”
“Qualcomm荣誉技术大使”是Qualcomm开发者社区对开发者用户技术能力与影响力的认证体现,该荣誉代表Qualcomm社区对用户贡献的认可与肯定。
立即申请招贤纳士
Qualcomm在中国的业务发展迅速,每年提供大量的技术岗位,分布在北京,上海,深圳等地。Qualcomm开发者社区是开发者藏龙卧虎之地,Qualcomm中国HR特别设立了招聘通道,欢迎开发者同学踊跃报名。