
QCS610的机器学习
使用异构计算运行推理工作负荷
Qualcomm® QCS610是一种专为低功耗、设备内置摄像头处理而设计的片上系统,可用于机器学习、边缘计算、语音用户界面启用、传感器处理、和集成无线连接等用例。该系统集成了Qualcomm®人工智能神经处理软件开发工具包和具有异构计算(中央处理器、图形处理器和数字信号处理器)架构的图像信号处理器(ISP)。
使用软件开发数据包完成以下任务:
1. 利用所支持的图层执行不同深度的神经网络。
2. 编写您自己的用户自定义图层(UDL)。
3. 利用Hexagon张量加速器(HTA)在Qualcomm® Adreno™图形处理器、Qualcomm® Kryo™中央处理器或Qualcomm® Hexagon™数字信号处理器上执行神经网络。
4. 利用内置转换工具将TensorFlow、Caffe、caff2和ONNX模型转换为深度学习容器(DLC)文件。
5. 在Hexagon数字信号处理器上,将深度学习容器文件量化为8位固定点。
6. 调试和分析神经网络的性能。
7. 通过Java或C++语言将神经网络集成到应用程序和其他代码中。
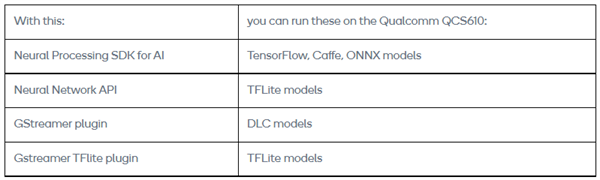
本页涉及以下内容:
• 人工智能神经处理软件开发工具包的开发工作流程和运行工作流程
• 将不同的机器学习模型转换为深度学习容器文件,以便在数字信号处理器上执行
• 利用软件开发工具包和GStreamer管道在QCS610上运行TensorFlow MobileNet单发多盒检测(SSD)网络的详细信息
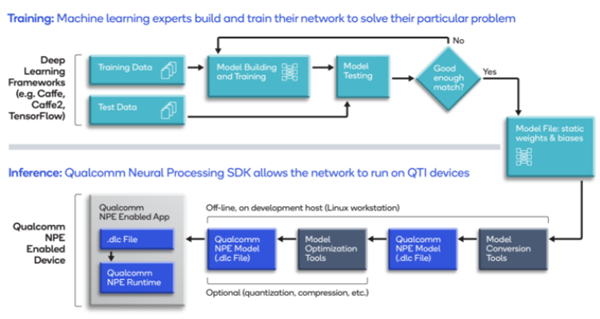
一、开发工作流程
1. 开发一个模型并对其进行培训,以满足应用程序的需求。
2. 利用模型的静态权重和偏差将其转换为软件开发工具包所使用的深度学习容器(DLC)格式。
3. 如要在Hexagon数字信号处理器上运行推理,使用软件开发工具包中的实用程序对模型进行量化和优化。
4. 使用软件开发工具包中的Java语言或C++语言应用程序接口开发机器学习应用程序,以便在Qualcomm Technologies的芯片组上运行转换后的模型。
5. 如果需要,可以使用软件开发工具包中的工具调试模型的性能和准确性。
二、运行时间工作流程
在转换和优化模型后,您可以使用本公司的神经处理软件开发工具包运行时间在Snapdragon ®处理器的中央处理器、图形处理器、和/或数字信号处理器上运行该模型。
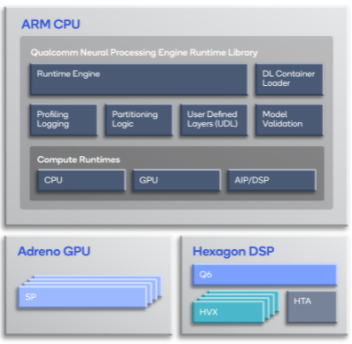
运行时间库的主要组成部分包括:
1. 深度学习容器加载器 – 加载由其中一种“snpe-framework-to-dlc”转换工具所创建的深度学习容器文件。
2. 模型验证 – 验证所加载的深度学习容器文件是否由所需要的运行时间支持。
3. 运行时间引擎 – 根据所请求的运行时间执行加载的模型,并收集支持用户自定义图层(UDL)和分析信息。
4. 分区逻辑 – 处理模型(包括验证所要求目标的图层),并根据需要按照其运行所要求的运行时间目标将模型分为子网。对于用户自定义图层,分区程序创建各个分区,以便按照中央处理器运行时间执行用户自定义图层。如果启用了中央处理器CPU回退,则分区程序将在目标运行时间所支持的图层和按照中央处理器运行时间上执行的其他图层(如果支持)之间对模型进行分区。
5. 中央处理器运行时间 – 在时——在支持32位浮点或8位量化执行的Kryo中央处理器上运行模型。
6. 图形处理器运行时间 – 在支持混合或完全16位浮点模式的Adreno图形处理器上运行模型。
7. 数字信号处理器运行时间 – 在使用Hexagon矢量扩展(HVX)的Hexagon数字信号处理器上运行模型,Hexagon矢量扩展非常适合机器学习算法常用的向量操作。
8. 人工智能处理器(AIP)运行时间 – 在使用Hexagon NN、Q6和Hexagon张量加速器(HTA)的Hexagon数字信号处理器上运行模型。
注解:人工智能处理器将Q6、Hexagon矢量扩展和Hexagon张量加速器抽象为一个实体的运行时间软件,控制着拥有所有三种硬件功能的神经网络模型的执行。
三、在Hexagon数字信号处理器上执行
软件开发工具包在数字信号处理器上加载一个与人工智能处理器通讯的程序库。如下图所示,数字信号处理器程序库包含一个数字信号处理器执行程序(用于管理跨Hexagon矢量扩展和Hexagon张量加速器模型的执行),用于在Hexagon张量加速器上运行子网的Hexagon张量加速器驱动程序,以及利用Hexagon矢量扩展运行子网的Hexagon NN。
数字信号处理器执行程序所使用的模型描述同样包含了分区信息。该项描述指定了模型的哪些部分将在Hexagon张量加速器上运行,哪些部分将在Hexagon矢量扩展上运行。所划分的部分被称为“子网”。
数字信号处理器执行程序在相应的核心上执行子网。该执行程序根据需要协调缓存交换、格式转换和反量化,以便将正确的输出量返回到ARM中央处理器上运行的Snapdragon运行时间。

四、转换模型以便在QCS610上运行 – TensorFlow示例
Qualcomm神经处理引擎软件开发工具包提供了将模型从Caffe/Caff2、TensorFlow、TFLite和ONNX转换为深度学习容器的工具。“入门页面”可以引导您完成软件开发工具包的设置。
以下步骤向您展示了如何将MobileNet v1 TensorFlow模型转换为.dlc文件,并在QCS610上运行.dlc。
注解:在执行此程序之前,请确保对软件开发工具包的环境进行初始化(“安装软件开发工具包”中的第5步)。
1. 该模型应该是一个冻结的图形,而Qualcomm神经处理引擎软件开发工具包需要将其转换为.dlc。运行以下命令,以便将tensorflow模型转换为.dlc:

2. 如要在数字信号处理器上运行转换后的.dlc模型,首先应当将其量化如下:
a.生成预处理原始图像文件。
b.创建raw_img_path.txt文件,然后将路径添加至“raw_img_path.txt”内所生成的原始图像文件中。
c.运行“snpe-dlc-quantize”,以便将模型量化:

注解:“snpe-dlc-quantize”生成名称为
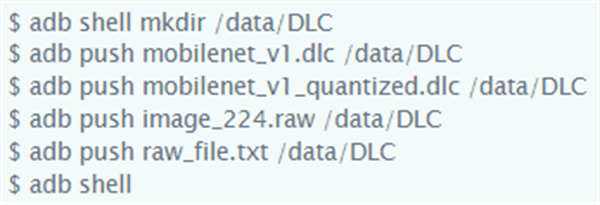
3. 使用USB-C线缆将主机系统连接至QCS610。然后,在主机系统上输入以下命令,将前面步骤中创建的.dlc文件和原始镜像文件推送到板上:
4. 利用该命令检查.dlc文件在不同委托下的通量:

注解:如要在不同的核心上运行模型,请将“--use_cpu”替换为“--se_gpu”或“--use_dsp”。(如要在数字信号处理器上运行,应当指定“--use_dsp”并将“mobilenet_v1_quantized.dlc”文件作为一个容器传送。)
五、使用GStreamer管道运行ML模型
除了使用软件开发工具包在Qualcomm QCS610上运行ML模型外,您还可以使用具有合适插件的GStreamer管道运行模型。
1. 使用GStreamer管道运行.dlc文件(qtimlesnpe插件)
GStreamer元素迅速将.dlc文件集成到可用的GStreamer插件中。GStreamer插件加载.dlc文件;对视频帧进行事前处理和后处理;配置软件开发工具包,以便在中央处理器、图形处理器、数字信号处理器、或Hexagon张量减速器上运行;并从软件开发工具包进行提取。
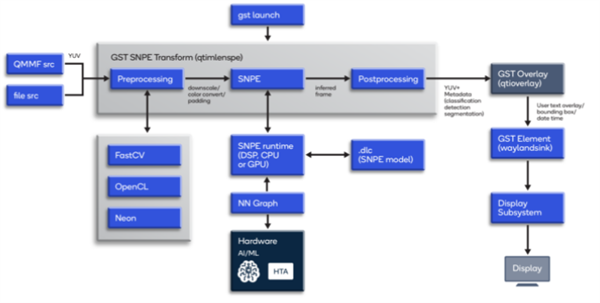
如图所示,在启动时,GStreamer管道会将摄像头源或文件源推断帧、连同一个.dlc文件传递给“qtimlesnpe”元素。“qtimlesnpe”元素使用软件开发工具包按照所请求的运行时间卸载模型计算。在“qtimlesnpe”元素中,推理结果被收集回来进行事后处理。
使用该GStreamer管道命令运行转换为.dlc文件的mobilenet模型:

2. 使用GStreamer管道运行TFLite模型(qtimletflite插件)
如要生成TFlite文件,在TensorFlow中对机器学习模型进行训练,然后冻结并转换为TFlite。接下来,模型进入神经网络应用程序接口运行时间,可以将模型卸载到Hexagon数字信号处理器。对于TFLite用例,可以使用GStreamer TFLite插件。将后处理的结果作为机器学习元数据提供给GStreamer缓存。利用神经网络应用程序接口,可以通过直接开发应用程序的方式来加速模型。
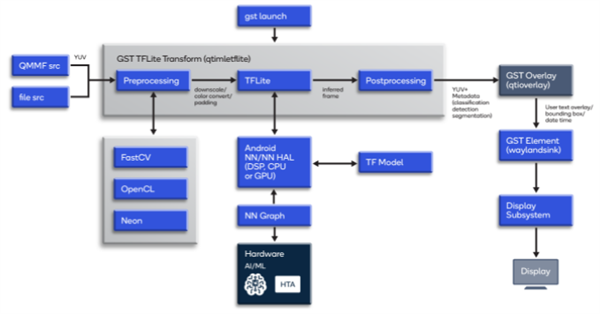
如图所示,在启动时,将摄像头源或文件源的推断帧发送到“qtimletflite”(GStreamer TFLite插件)。TFLite运行时间可以在中央处理器、数字信号处理器或图形处理器上运行。该类模型适用于单独主机上的TF。对于后处理,推理结果被收集回GStreamer TFLite插件中。
使用该GStreamer管道命令运行TFLite转换的mobilenet模型:

“qtimletflite”插件使用了神经网络应用程序接口,这是一种安卓C型应用程序接口,可以对安卓设备中央处理器、图形处理器和Hexagon数字信号处理器上的TFLite模型进行加速。
如要了解更多的背景和信息,请参考以下相关页面:
1. https://developer.qualcomm.com/docs/snpe/overview.html
2. https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk
3. https://developer.qualcomm.com/docs/snpe/snapdragon_npe_runtime.html
4. https://developer.qualcomm.com/docs/snpe/aip_runtime.html
6. https://developer.android.com/ndk/guides/neuralnetworks
Qualcomm QCS610、Qualcomm Kryo、Qualcomm Adreno、Qualcomm Hexagon、Snapdragon和Qualcomm神经处理软件开发工具包均为Qualcomm Technologies, Inc.和/或其子公司的产品。
Qualcomm 开发者专区是 Qualcomm 联合CSDN 共同打造的面向中国开发者的技术专区。致力于通过提供全球最新资讯和最多元的技术资源及支持,为开发者们打造全面一流的开发环境。本专区将以嵌入式、物联网、游戏开发、Qualcomm® 骁龙™处理器的软件优化等技术为核心,打造全面的开发者技术服务社区,为下一代高性能体验和设计带来更多的想法和灵感。
加入 Qualcomm 开发者专区

申请成为“Qualcomm荣誉技术大使”
“Qualcomm荣誉技术大使”是Qualcomm开发者社区对开发者用户技术能力与影响力的认证体现,该荣誉代表Qualcomm社区对用户贡献的认可与肯定。
立即申请招贤纳士
Qualcomm在中国的业务发展迅速,每年提供大量的技术岗位,分布在北京,上海,深圳等地。Qualcomm开发者社区是开发者藏龙卧虎之地,Qualcomm中国HR特别设立了招聘通道,欢迎开发者同学踊跃报名。