
删除未使用的渲染目标
避免增加GPU工作负载、但无任何好处的调用。
图形内存(GMEM)是Qualcomm® Adreno™ GPU中的宝贵资源。GPU根据帧缓存大小生成图块,然后通过解析图片重建主内存曲面。此操作称为GMEM存储。更多渲染目标意味着更多的图片,也即更多GMEM存储操作,性能损失的可能性更大。
我们可以将GMEM比作GPU高速L1缓存。将任何内容加载到缓存中的代价都很昂贵,除非确有必要,否则我们应该竭力避免。同样,将缓存中的任何内容存储到非平铺内存中的代价也很高,因此,除非确有必要,否则应该避免。
在Snapdragon Profiler中使用“跟踪捕获”模式,允许“渲染阶段”指标在各自轨迹中突出显示GMEM存储。
以下截图基于演示应用程序Depth of Field。底部的紫色块表示在渲染三个不同表面(缩减比例和模糊帧缓冲对象)时,深度模板和颜色正在发生GMEM存储:
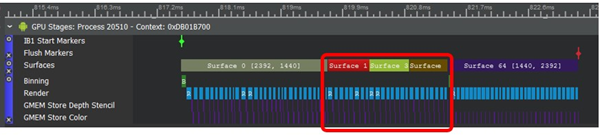
单击这些曲面将打开“检查器”(Inspector)视图,其中包含曲面块的属性。如下图所示,如果存在颜色、深度和模板附件,将出现在此视图中:
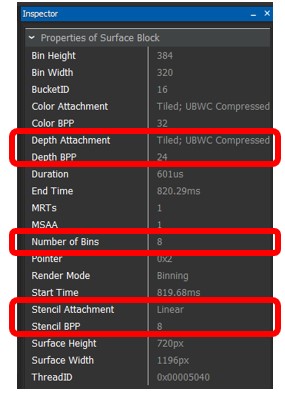
Inspector视图是遍历所有绘制曲面的快速方法,用于查找附加不需要的渲染目标的曲面。如图所示,帧视图表示缩减和模糊帧缓冲对象拥有不需要的深度和模板附件,仅仅是在做着无用功。
(“渲染目标”是高级图形API使用的术语。“binning”是Adreno GPU将特定大小的渲染目标划分为一个或多个图元,以便通过GMEM硬件处理这些区域。一个GMEM图块大致相当于1个图元(bin)。)
优化所选曲面的代码后,可以在“跟踪捕获”模式下验证结果:
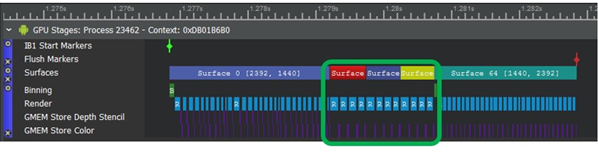
深度和模板GMEM存储停止,因此三个曲面的渲染中断较少。曲面“检查器”视图仍显示“颜色”附件,但“深度”和“模板”附件不存在:
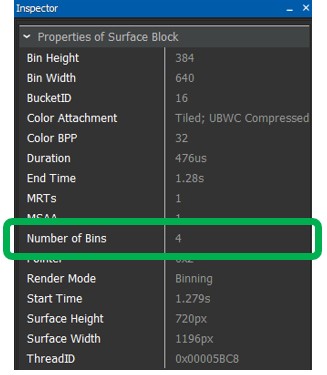
此外,渲染的图元数从8减少到4。(本例中渲染数从8减少到4,具体根据特定应用程序和工作负载而定。一般而言,不可能,或者说不容易准确预测减少的数量,因为有数个特定于平台的变量在发挥作用,包括GMEM图片大小和配置以及binning过程的情况。)
在本例中,曲面渲染时间从601毫秒减少到475毫秒,整帧时间约减少5%。
Qualcomm 开发者专区是 Qualcomm 联合CSDN 共同打造的面向中国开发者的技术专区。致力于通过提供全球最新资讯和最多元的技术资源及支持,为开发者们打造全面一流的开发环境。本专区将以嵌入式、物联网、游戏开发、Qualcomm® 骁龙™处理器的软件优化等技术为核心,打造全面的开发者技术服务社区,为下一代高性能体验和设计带来更多的想法和灵感。
加入 Qualcomm 开发者专区

申请成为“Qualcomm荣誉技术大使”
“Qualcomm荣誉技术大使”是Qualcomm开发者社区对开发者用户技术能力与影响力的认证体现,该荣誉代表Qualcomm社区对用户贡献的认可与肯定。
立即申请招贤纳士
Qualcomm在中国的业务发展迅速,每年提供大量的技术岗位,分布在北京,上海,深圳等地。Qualcomm开发者社区是开发者藏龙卧虎之地,Qualcomm中国HR特别设立了招聘通道,欢迎开发者同学踊跃报名。
Qualcomm 活动 更多
6月19日
线上