
高通神经处理SDK
高通技术公司出品

高通® 神经处理SDK有助于开发者节约开发时间和工作量,针对配备高通®人工智能产品的设备,优化经过训练的神经网络的性能。作为高通® 人工智能软件栈的一员,它可以帮助开发者快速部署人工智能模型,完全运行在高通®人工智能产品的设备端。
我们的产品拥有各种人工智能处理能力,可以在设备上运行经过训练的神经网络,无需连接到云端。高通神经处理 SDK 旨在帮助开发者在 高通® 平台上(不管是CPU、GPU还是高通® Hexagon™ 处理器)运行一个或多个使用TensorFlow、PyTorch、Keras 或 ONNX 训练的神经网络模型。
高通神经处理 SDK 提供模型转换和执行工具以及API,使用功耗和性能配置文件,匹配相应的用户体验。此外,本 SDK 还支持卷积神经网络和自定义层。
高通神经处理SDK执行了在高通® 平台上运行神经网络所需的大量繁重工作,为开发者节约了更多时间和资源,可以专注于构建其他创新的用户体验。

SDK内含:
• Android和Linux运行时,执行神经网络模型
• 支持高通® Hexagon™ 处理器、高通® Adreno™ GPU和 高通® Kryo™、CPU加速1
• 支持TensorFlow、PyTorch、Keras和ONNX格式的模型2
• 提供控制运行时加载、执行和调度的API
• 供模型转换的桌面工具
• 识别瓶颈的性能基准
• 示例代码和教程
• HTML文档
为方便AI开发者,高通神经处理SDK没有另外定义一个网络层库;相反,在发布时就直接支持TensorFlo、PyTorch、Keras 和 NNX,因此,开发者可以自由使用熟悉的框架,设计和训练网络。相关流程如下:
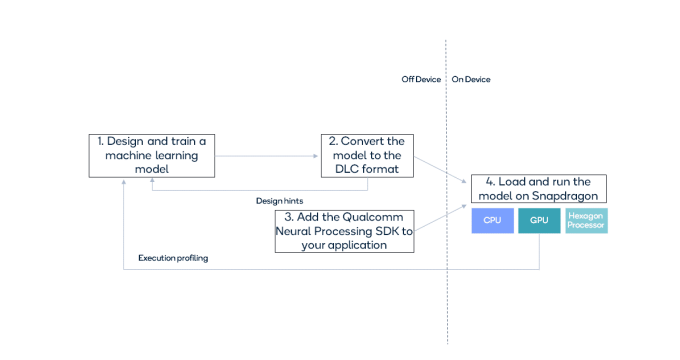
设计和培训后,模型文件需要转换成“.dlc”(深度学习容器)文件,供骁龙®神经处理引擎(NPE)运行时使用。转换工具将输出转换信息,包括有关不支持或非加速层的信息,供开发者调整初始模型的设计。
高通人工智能神经处理SDK是否适合您?
使用高通神经处理SDK开发人工智能解决方案需要具备以下基本前提。
• 需要在一个或多个垂直领域运行卷积模型,包括移动、计算、汽车、物联网、增强现实、无人机和机器人
• 知道如何设计和训练模型或已经有预先训练过的模型文件
• 选择的框架为:TensorFlow、PyTorch,Keras 和 ONNX
• 为Android开发JAVA应用,或为Android、Windows 或Linux 开发原生应用程序
• Ubuntu 20.04 或者 WSL2 on Windows(具有Ubuntu 20.04开发环境)
• 拥有一台支持设备,测试应用程序
有关其他用途或需求,请通过支持论坛和我们取得联系。
论坛和反馈
我们欢迎您就高通神经处理SDK提出反馈和问题。您可以访问高通神经处理SDK论坛,浏览常见问题的答案,注册并发布新主题,跟踪有关主题的更新内容,或者回答其他机器学习爱好者提出的问题。
1.高通神经处理 SDK 支持骁龙 CPU
2.由于网络和层发展迅速,加速支持仅覆盖部分,将来会予扩展。
骁龙和高通品牌产品是 高通技术公司和/或其子公司的产品。
Qualcomm 开发者专区是 Qualcomm 联合CSDN 共同打造的面向中国开发者的技术专区。致力于通过提供全球最新资讯和最多元的技术资源及支持,为开发者们打造全面一流的开发环境。本专区将以嵌入式、物联网、游戏开发、Qualcomm® 骁龙™处理器的软件优化等技术为核心,打造全面的开发者技术服务社区,为下一代高性能体验和设计带来更多的想法和灵感。
加入 Qualcomm 开发者专区

申请成为“Qualcomm荣誉技术大使”
“Qualcomm荣誉技术大使”是Qualcomm开发者社区对开发者用户技术能力与影响力的认证体现,该荣誉代表Qualcomm社区对用户贡献的认可与肯定。
立即申请招贤纳士
Qualcomm在中国的业务发展迅速,每年提供大量的技术岗位,分布在北京,上海,深圳等地。Qualcomm开发者社区是开发者藏龙卧虎之地,Qualcomm中国HR特别设立了招聘通道,欢迎开发者同学踊跃报名。