
C6490-MobileVLM-cn
| 操作系统 | 云服务/平台 | 所需技能水平 | 关注领域 |
|---|---|---|---|
| Linux Ubuntu核心 | --- | 中级 |
计算机视觉、嵌入 |
项目目标
MobileVLM是多模态视觉语言模型 (MMVLM),llama.cpp通过Meta的LLaMA模型(以及其他模型)在纯 C/C++中的推理,实现端侧性能的高效性。同时可以应用于智能机器人领域,实现智能特性。
项目说明
MobileVLM 是一种强大的多模态视觉语言模型 (MMVLM),旨在在移动设备上运行。 它是无数面向移动的架构设计和技术的融合,其中包括一组从头开始训练的 1.4B 和 2.7B 参数规模的语言模型,以及在以下环境中预训练的多模态视觉模型: 通过高效投影仪进行 CLIP 时尚、跨模态交互。 根据几个典型的 VLM 基准评估 MobileVLM。 与一些更大的模型相比,模型表现出了同等的性能。
所需材料/零部件清单/工具
• USB Line
• Charger
高通 C6490P DK套件

Type-c 数据线

电源

源代码/源示例/可执行应用程序
• 源代码
额外资源
• 视频链接:https://github.com/ThunderSoft-XA/MobileLLVM-on-6490/blob/main/doc/usage.mp4
• MobileVLM原始模型: https://huggingface.co/liuhaotian/llava-v1.5-7b
https://huggingface.co/openai/clip-vit-large-patch14-336
构建/汇编指令
cd cpp/source
mkdir build & cd build
cmake /
make -j6
make llava-cli
cp bin/llava-cli ..
cd..
./llava-cli -m ../model/ggml-model-q4_k.gguf --mmproj ../model/mmproj-model-f16.gguf --image ../input/input.jpg -p 'what is it in the picture'
使用说明
在主函数对应位置修改图片路径,后编译运行。默认输出位置为output/0.jpg。 运行结果如下:
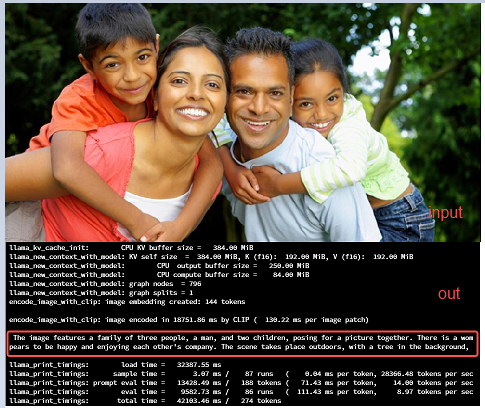
提供人信息
| 姓名 | 名称公司 |
|---|---|
| zhangzz6687@thundersoft.com | 中科创达 |
| yunlong.zhao@thundercomm.com |
中科创达 |
如提交有关内容(以下简称为“提交内容”),则表明您向高通公司授予有关以下各项的免费、永久性、非排他性、不受限制、全球范围内的许可:(a)公布、使用、复制、转授、改编、传输、公开执行或展示提交内容;(b)在没有限制条件的情况下使用、复制、修改、改编、发布、翻译、创作衍生作品、分发、执行、演示、托管、提供和发布您的提交内容;(c)向第三方转授无限制的行使针对提交内容所授予的前述任何权利的权利。前述权利应当包括利用提交内容中的任何理念、概念、知识产权、或专有权利的权利,包括但不限于在任何相关司法管辖区内根据著作权、商标、服务标记或专利等法律所享有的权利,同时高通公司无须向您支付任何款项。您声明并保证,您拥有有关提交内容的所有权利、所有权和权益,或您已被授予有关提交内容的充分权利,以确保能够按照前述方式使用提交内容。
Qualcomm 开发者专区是 Qualcomm 联合CSDN 共同打造的面向中国开发者的技术专区。致力于通过提供全球最新资讯和最多元的技术资源及支持,为开发者们打造全面一流的开发环境。本专区将以嵌入式、物联网、游戏开发、Qualcomm® 骁龙™处理器的软件优化等技术为核心,打造全面的开发者技术服务社区,为下一代高性能体验和设计带来更多的想法和灵感。
加入 Qualcomm 开发者专区

申请成为“Qualcomm荣誉技术大使”
“Qualcomm荣誉技术大使”是Qualcomm开发者社区对开发者用户技术能力与影响力的认证体现,该荣誉代表Qualcomm社区对用户贡献的认可与肯定。
立即申请招贤纳士
Qualcomm在中国的业务发展迅速,每年提供大量的技术岗位,分布在北京,上海,深圳等地。Qualcomm开发者社区是开发者藏龙卧虎之地,Qualcomm中国HR特别设立了招聘通道,欢迎开发者同学踊跃报名。